For each input multiple alignment the workflow calculates the consensus and saves it to a text file, named according to the name of the input alignment.
The JalView algorithm (denoted as "default") is used by default to calculate the consensus. For each column of the alignment it returns either "+", if there are 2 characters with high frequency in this column, or a character in uppercase or lowercase. The case of the character depends on the percentage value of the character in the column and the "threshold" value.
Alternatively, you can use the ClustalW algorithm to calculate the consensus:
- If all characters in a column are exactly the same, the algorithm sets asterisk value ("*") to the corresponding position of the consensus.
- A colon value (":") indicates conservation between groups of strongly similar properties, i.e. the scoring value is greater than 0.5 in the Gonnet PAM 250 matrix (see documentation for details).
- If the scoring value is less than 0.5, the period (".") value is inserted.
- Otherwise, the algorithm inserts space (" ").
The "threshold" parameter is not applied to this algorithm.
How to Use This Sample
If you haven't used the workflow samples in UGENE before, look at the "How to Use Sample Workflows" section of the documentation.
Workflow Sample Location
The workflow sample "Extract Consensus as Text" can be found in the "Alignment" section of the Workflow Designer samples.
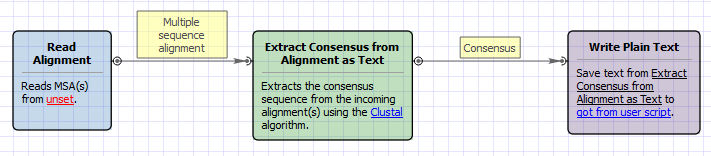
Workflow Image
The workflow looks as follows:
Workflow Wizard
The wizard has 3 pages.
Input Multiple Alignments: On this page you must input multiple alignments file(s).
Extracting Consensus Settings: On this page you can modify extracting settings.
Output Files: For each input alignment the workflow outputs separate sequence file with consensus in it.